

Anselm corpus
The project Questions by St. Anselm about the Lord’s Passion, funded by DFG, deals with a popular medieval dialogue between Anselm of Canterbury and Saint Mary. The text has been preserved in various German dialects in more than 60 manuscripts and prints from the 14th–16th centuries, all of which have been transcribed and are currently being annotated. The ultimate goal of the project is to use the corpus for various cross-linguistic investigations, such as comparing spelling or word-order variation between different dialects. Sample data is already available and can be searched via ANNIS.

Reference corpora of historical German
We are part of two DFG-funded projects for creating annotated reference corpora of historical German: Reference corpus Middle High German and Reference corpus Early New High German. These projects are complemented by two further, ongoing projects, dealing with Old German and Middle Low German, respectively. The four corpora are transcribed diplomatically (i.e. close to the original manuscripts) and annotated with lemma, morphology, and part of speech. They follow similar guidelines, which will allow us eventually to merge the annotated corpora and create one large, diachronic corpus of German.
Website of the reference corpora for Middle and Early New High German

Tools and Guidelines
Our main focus is on developing methods and tools for analyzing historical data. For this, we first create annotation guidelines and annotate data manually. The data can then be used as training data for automatic tools. We currently work on:
- Web-based Annotation
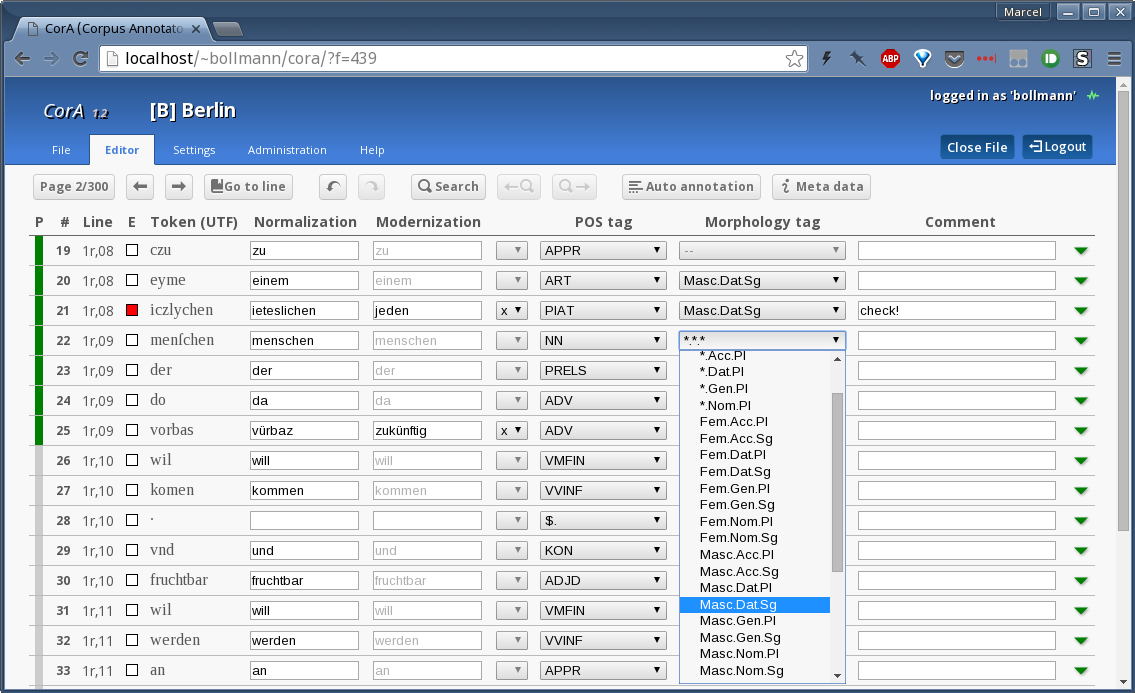
- We developed our own web-based annotation tool, CorA, which includes features such as integrating external POS taggers and editing the primary data. Website of CorA (Corpus Annotator)
- Normalization
- Mapping different spellings to a uniform wordform, both manually and (semi-)automatically. For the latter, we developed our own normalization tool. Website of Norma (Normalization Tool)
- Segmentation
- Segmenting the dialogues in the Anselm corpus in turns (consisting of Anselm’s questions and Mary’s answers), sentences, and smaller chunks.
- Part-of-speech and morphological tagging
- Annotating each word with its part of speech and morphological analysis. For the reference corpora, we use HiTS, a tagset specifically adapted for historical German. Website of HiTS (Historical TagSet)
- Alignment and cue words
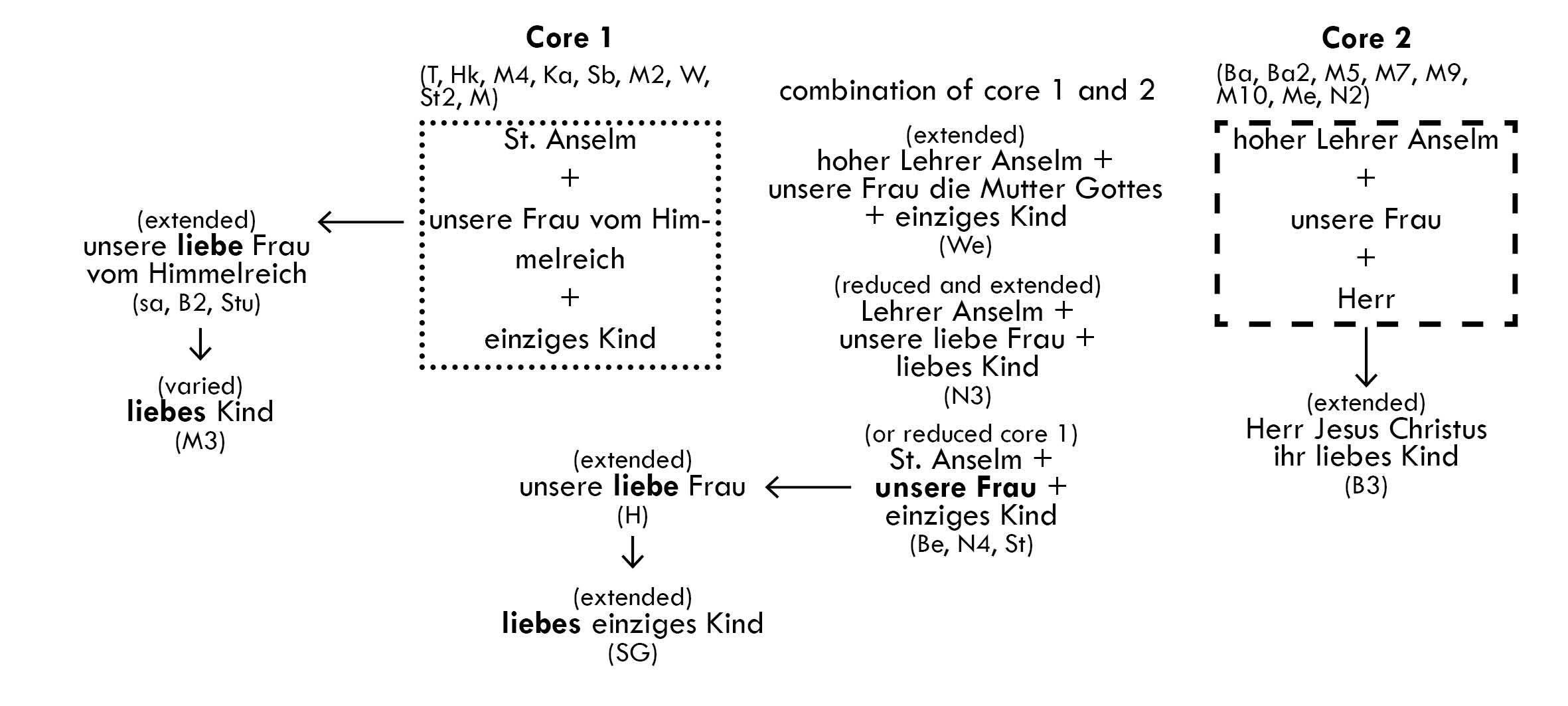
- Aligning corresponding words and phrases (roughly translational equivalents) across the manuscripts of the Anselm corpus, and marking terms that refer to important persons or concepts (such as “Saint Mary” or “Last Supper”). More…
Source Code
Source code for the tools we develop can be found on Github: Our Github profile