Alignment Guidelines
The Anselm Corpus is comprised of 62 vernacular manuscripts and prints. They all represent different versions of the medieval tract Interrogatio Sancti Anselmi de Passione Domini. Due to the considerable proportion of similarity between those versions, we developed guidelines for aligning corresponding elements (words, phrases, paragraphs) between them. Two tokens (or phrases) are taken to correspond if they share the same context, as in the following example:
- Bamberg (Ba1)
- Ain hoher lerer hiesz anshelmus, der pat vnser frauen lange weill vnd zeit wainent vasten vnd peten, Das sy im zu erkennen geb, wie vnser herre gemartert wer word
‘A high teacher was called Anselm, he asked our lady for a long time, crying, starving, praying, for that she signifies him how our lord was tortured’ - Dessau (D4)
- Sant anszhelmüs / / bischoff hat gebetten lang zeit mit vasten / weinen vnnd betten / Maria die reinen Iuncfrowen vnd müter gots / das si Im wolt volkomenlich offenbaren / das leyden Ires lieben soenes cristi iesu
‘Saint Anselm, the bishop, has asked long time – while starving, crying and praying – Mary, the pure virgin and mother of god, to completely reveal the passion of her son Jesus Christ ’
Annotation Layers
In the guidelines, we distinguish between four separate annotation layers:
-
Cognates: On this layer, all corresponding tokes that are cognates, i.e. words with a common etymological origin, are aligned.
-
Synonyms: On this layer, real synonyms of the type token:token are aligned. Tokens are taken to be synonyms if they can be used interchangeably without a change in meaning.
-
Coreference: On this layer, coreferent phrases are aligned, i.e. a pro-form in one manuscript and a corresponding full phrase in the other manuscript.
-
Complex (phrasal) equivalents (CPE): In a last annotation pass, all remaining not-aligned tokens are checked for correspondence. On this layer, only complex corresponding phrases can be aligned.
Evaluation
For evaluating our guidelines, two annotators independently aligned the first 500 words of two Anselm text pairs: one with to similar Anselm versions (Ba1 and Ba2), the other with two dissimilar Anselm versions (Ba1 and D4). Figure 1, displaying the links between Ba1 and Ba2, indicates that the correlation between both fragments is almost perfect (aligning a text with itself would result in a diagonal). The plot of the dissimilar texts (Fig. 2), Ba1 and D4, still clearly approximates the diagonal, which mirrors the fact that both fragments have the same topic. At the same time, it shows considerable deviations and alignment gaps. For the alignment task, the annotators used the annotation tool MMAX2, which allows to display two text adjacently to each other. As a measure of the inter-annotator agreement, we used Word Alignment Agreement (WAA) and the chance-corrected kappa score. If we merge all four layers in one, the annotator agreement on the alignment as such is very high, while the decision about the type of alignment (i.e. its layer) is more controversial. Here, the best results are attained for the cognate and synonym layer while annotating the co-reference and CPE layer seems to be a considerably difficult task.
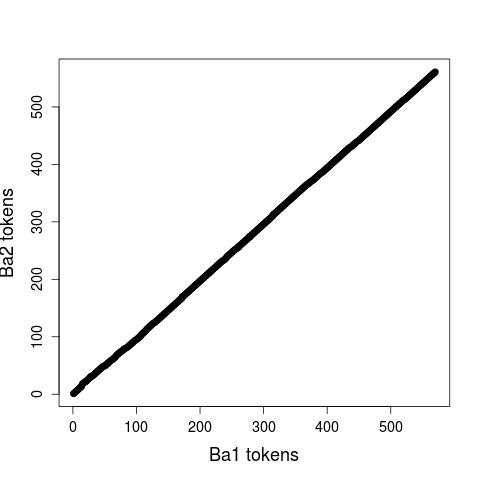 Figure 1: Plot of the aligned token positions in the similar fragments (Ba1:Ba2)
Figure 1: Plot of the aligned token positions in the similar fragments (Ba1:Ba2)
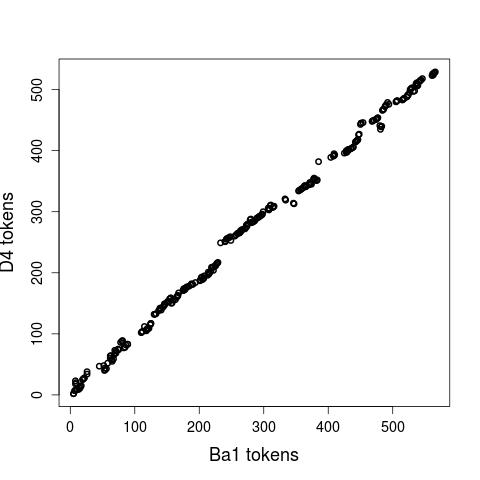 Figure 2: Plot of the aligned token positions in the dissimilar fragments (Ba1:D4)
Figure 2: Plot of the aligned token positions in the dissimilar fragments (Ba1:D4)
 Figure 3: Screenshot of alignment annotations in MMAX2
Figure 3: Screenshot of alignment annotations in MMAX2
Application
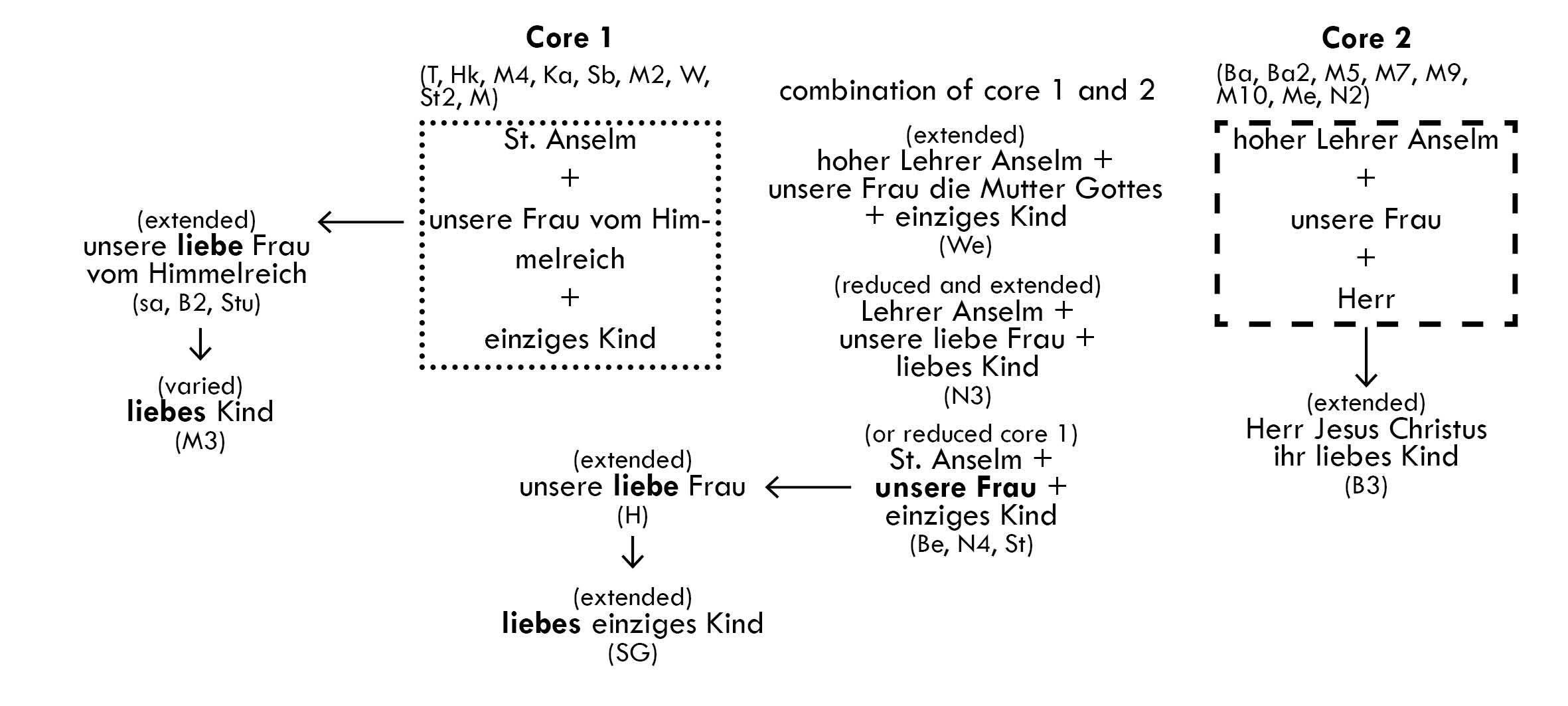
The alignments can be used for answering philological questions. Our assumption is that groups and sub-groups of the Anselm texts can be visualized by using alignments and measuring distance between annotated keywords. Such keywords are, for example, references to the persons ‘Anselm’, ‘Mary’ and ‘Jesus Christ’. All three of them are referred to by different terms, e.g. ‘(dear) lady from heaven’, ‘mother of god’ or ‘rose, lily and perennial’ for Mary. The alignment reveals that the Anselm texts can be arranged in clusters according to the usage of those key terms (Fig. 4).
Publications
The alignment guidelines have been described in the following work:
- Stefanie Dipper, Julia Krasselt, and Simone Schultz-Balluff (2015). Creating synopses of ‘parallel’ historical manuscripts and early prints. Alignment guidelines, evaluation, and applications. In: Historical Corpora, Challenges and Perspectives (= CLIP 5). Tübingen: Narr. [PDF preprint]